1. false sharing 이란??
false sharing은 멀티 쓰레드 환경 + CPU의 멀티 코어에서 발생됩니다.
cpu 내부의 코어와 코어간의 메모리 정보가 공유되어 하드웨어 적으로 병목현상이 일어나는 것을 뜻합니다.
설명하기에 앞서 false sharing이 일어난 코드를 보겠습니다.
#include <iostream>
#include <thread>
#include <chrono>
long long num1 = 0;
long long num2 = 0;
long long num3 = 0;
void fun1() {
for (long long i = 0; i < 1000000000; i++)
num1 += 1;
}
void fun2() {
for (long long i = 0; i < 1000000000; i++)
num2 += 1;
}
void fun3() {
for (long long i = 0; i < 2000000000; i++) {
num3 += 1;
}
}
int main() {
auto beginTime = std::chrono::high_resolution_clock::now();
std::thread t1(fun1); //Multi Thread 실행
std::thread t2(fun2); //Multi Thread 실행
t1.join(); t2.join();
auto endTime = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> resultTime = endTime - beginTime;
printf("%lld\n", num1 + num2);
std::cout << resultTime.count() << std::endl;
printf("--------------------\n");
beginTime = std::chrono::high_resolution_clock::now();
fun3(); //Single Thread 실행
endTime = std::chrono::high_resolution_clock::now();
resultTime = endTime - beginTime;
printf("%lld\n", num3);
std::cout << resultTime.count() << std::endl;
}
코드는 길어보이지만 간단한 코드 입니다.
thread t1, t2는 fun1()과 fun2()를 실행하는 거고요.
fun3()은 일반적인 함수 호출로 실행되는 겁니다.
결과

9.34802초가 걸린 것이 Multi thread로 계산한 결과이고,
3.33701이 Single thread로 계산한 결과입니다.
비슷하거나 빨라야 하는데 1초 차이도 아니고 6초 차이가 나버립니다.
왜 그럴까요??
이 현상을 알기 위해 CPU의 캐시구조를 알 필요가 있습니다.
2. CPU의 캐시 구조
요즘 나오는 CPU들은 L1과 L2캐시가 코어에 있고 L3는 외부에 따로 나와있습니다.
저희집 CPU는 i5-8400인데 해당 스팩은 다음과 같습니다.
코어로 전달되는 Cache Line, L1, L2, L3에 저장될 수 있는 용량은 사진과 같습니다.
L3캐시는 메모리로부터 자료를 받아옵니다. 그럼 해당 데이터를 L2 -> L1순으로 전달하게 됩니다.
그럼 각각 L1캐시에는 long long num1과 long long num2의 데이터가 있을 것입니다.
왜??
캐시는 자주 사용하는 데이터를 메모리까지(ram) 가지 않고 메모리보다 더 빠른 캐시에 저장함으로서
좀 더 빠르게 데이터를 처리하려고 하죠.
그럼 t1과 t2스레드가 연산을 처리하는 과정을 그림으로 나타내 보겠습니다.
이런식으로 들어오게 됩니다.

(※CPU 스팩에서 알 수 있듯이 CPU는 Cache Line에서 64byte씩 읽어 데이터를 처리합니다.
해당 블록은 8바이트가 4개 있는 것이며 이해를 돕기위해 간단하게 표시했습니다.)
Core 1. Core 2에는 num1과 num2가 있습니다. 그 이유는 캐시에서 64byte씩 통째로 읽어오기 때문입니다.
(이렇게 된 이유는 예제 코드에서의 num1과 num2가 붙어있기 때문에 64byte씩 읽어오게 될 경우,
데이터에 두개의 변수 정보가 들어갈 확률이 높습니다.)
그래서 Core 2는 문제없이 연산하게 됩니다.
하지만 Core 1은 좀 다릅니다.
CPU에서는 캐시 일관성(cache coherence)이라는 메커니즘이 존재합니다.
CPU는 그냥 계산만 처리하는 기계입니다.
비록 Core 1에서 num2의 계산을 하지 않지만, 캐시 입장에선 데이터가 공유되어 무슨일이 일어날지 알 수 없습니다.
따라서 Core 1의 연산을 멈추고 num2의 값을 다시 받아옵니다.
일종의 동기화 작업입니다.
이는 데이터의 오류를 줄이고자 진행되는 매커니즘입니다.Thread에서의 lock과 같다고 생각하면 됩니다.
따라서 Core 1은 Core 2의 num2가 사라질 때 까지(데이터 처리가 끝날 때 까지) num2 값을 계속 받아오게 됩니다.어떻게 받아오느냐? 갖고 있던 기존 64bit를 버리고 캐시에서 다시 받아오게 됩니다.
그럼 Core 2는 계속 num2의 데이터 처리를 진행할까요?? 아닙니다.인텔 프로세스의 프로토콜인(MESI)에 의거하여 해당 데이터를 공유로 처리하고,캐시 데이터에 기록을 계속하게 됩니다.
때문에 엄청난 성능 저하를 일으켜 위와 같은 시간 차이가 나온 것입니다.
이를 해결하는 방법은 패딩(padding)을 이용해 데이터를 64바이트로 채워주는 것입니다.
그럼 캐시간 데이터가 공유되는 상황을 막을 수 있습니다.

이런식으로 말이죠.....
C++에서 제공하는 alignas()함수를 이용해 데이터에 패딩을 채워줄 수 있습니다.
아래는 패딩으로 채워준 코드입니다.
#include <iostream>
#include <thread>
#include <chrono>
alignas(64) long long num1 = 0; //바뀐 부분
alignas(64) long long num2 = 0; //바뀐 부분
long long num3 = 0;
void fun1() {
for (long long i = 0; i < 1000000000; i++)
num1 += 1;
}
void fun2() {
for (long long i = 0; i < 1000000000; i++)
num2 += 1;
}
void fun3() {
for (long long i = 0; i < 2000000000; i++) {
num3 += 1;
}
}
int main() {
auto beginTime = std::chrono::high_resolution_clock::now();
std::thread t1(fun1); //Multi Thread 실행
std::thread t2(fun2); //Multi Thread 실행
t1.join(); t2.join();
auto endTime = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> resultTime = endTime - beginTime;
printf("%lld\n", num1 + num2);
std::cout << resultTime.count() << std::endl;
printf("--------------------\n");
beginTime = std::chrono::high_resolution_clock::now();
fun3(); //Single Thread 실행
endTime = std::chrono::high_resolution_clock::now();
resultTime = endTime - beginTime;
printf("%lld\n", num3);
std::cout << resultTime.count() << std::endl;
}
제대로 동작 하니 1.67077초가 걸렸습니다.
9초랑 엄청 차이가 나죠??
해당 fun1(), fun2() 는 컴파일 과정에서 최적화 과정이 일어나 많은 차이를 보여줬는데, 난수를 사용해서 최적화 과정을 없애보겠습니다.
False sharing example
#include <iostream>
#include <thread>
#include <chrono>
#include<cstdlib>
volatile long long num1 = 0; //바뀐 부분
volatile long long num2 = 0; //바뀐 부분
volatile long long num3 = 0;
void fun1() {
for (long long i = 0; i < 100000000; i++)
num1 += rand();
}
void fun2() {
for (long long i = 0; i < 100000000; i++)
num2 += rand();
}
void fun3() {
for (long long i = 0; i < 200000000; i++) {
num3 += rand();
}
}
int main() {
auto beginTime = std::chrono::high_resolution_clock::now();
std::thread t1(fun1); //Multi Thread 실행
std::thread t2(fun2); //Multi Thread 실행
t1.join(); t2.join();
auto endTime = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> resultTime = endTime - beginTime;
printf("%lld\n", num1 + num2);
std::cout << resultTime.count() << std::endl;
printf("--------------------\n");
beginTime = std::chrono::high_resolution_clock::now();
fun3(); //Single Thread 실행
endTime = std::chrono::high_resolution_clock::now();
resultTime = endTime - beginTime;
printf("%lld\n", num3);
std::cout << resultTime.count() << std::endl;
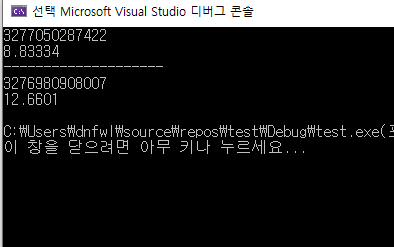
}
Add padding to variables
#include <iostream>
#include <thread>
#include <chrono>
#include <cstdlib>
alignas(64) volatile long long num1 = 0; //바뀐 부분
alignas(64) volatile long long num2 = 0; //바뀐 부분
volatile long long num3 = 0;
void fun1() {
for (long long i = 0; i < 100000000; i++)
num1 += rand();
}
void fun2() {
for (long long i = 0; i < 100000000; i++)
num2 += rand();
}
void fun3() {
for (long long i = 0; i < 200000000; i++) {
num3 += rand();
}
}
int main() {
auto beginTime = std::chrono::high_resolution_clock::now();
std::thread t1(fun1); //Multi Thread 실행
std::thread t2(fun2); //Multi Thread 실행
t1.join(); t2.join();
auto endTime = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> resultTime = endTime - beginTime;
printf("%lld\n", num1 + num2);
std::cout << resultTime.count() << std::endl;
printf("--------------------\n");
beginTime = std::chrono::high_resolution_clock::now();
fun3(); //Single Thread 실행
endTime = std::chrono::high_resolution_clock::now();
resultTime = endTime - beginTime;
printf("%lld\n", num3);
std::cout << resultTime.count() << std::endl;
}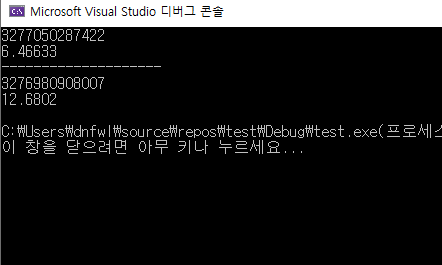
컴파일 최적화 과정을 거치지 않은 for문의 결과입니다.
2초정도 차이가 나네요. 이게 최적화 과정을 거치지 않은 정확한 결과입니다.
그럼, 최적화가 일어날 수 있는 경우라면 맨 위 두개의 예제처럼 더 큰 차이가 날 것입니다.
C++에선 컴파일러의 최적화 과정이 매우 중요하고, 프로그램 퍼포먼스에 중요한 역할을 하니 참고하시면 좋을 것 같습니다.
자신의 CPU캐시의 크기를 얻어오는 메크로도 존재합니다.
std::hardware_destructive_interference_size 를 이용하면 됩니다.
이 외에도 struct나 class단위도 데이터를 맞춰줄 수 있습니다.
class alignas(32) A {
private:
int num;
char c;
int arr[10];
};
struct alignas(64) B {
private:
int num;
char c;
int arr[10];
};
윈도우의 visual studio에서는 같은 기능을 제공하는 명령어가 있습니다.
__declspec(align(#)) 기능으로 말이죠.
class __declspec(align(64)) A { //위치는 상관 없음
private:
int num;
char c;
int arr[10];
};
__declspec(align(64)) struct B { //위치는 상관 없음
private:
int num;
char c;
int arr[10];
};
패딩말고도 변수를 할당할 때 주소 값이 떨어지게끔 다른곳에 선언하거나,
openMP를 활용해 제어하는 방법이 있습니다.
참고 래퍼런스 :
http://www.cpu-world.com/CPUs/Core_i5/Intel-Core%20i5%20i5-8400.html
https://medium.com/@teivah/go-and-cpu-caches-af5d32cc5592
혹시 잘못된 설명이나 오류가 있다면 댓글로 피드백 달아주세요!!
환영입니다.!!
'프로그래밍 > 컴퓨터 과학(CS)' 카테고리의 다른 글
| 1편] 동기와 비동기 블로킹과 논블로킹에 대해서.... (0) | 2020.09.07 |
|---|---|
| C++ 클래스와 구조체의 데이터 정렬(Data alignment) 왜 데이터 크기가 다르지? (1) | 2020.06.24 |
| C++ 에서의 OOP의 개념에 대한 설명(Abstraction, Encapsulation, Inheritance, Polymorphism) (0) | 2020.06.21 |
| Thread와 Process의 Context Switching (0) | 2020.06.05 |
| CPU와 메모리 사이의 동작 (2) | 2019.12.10 |



댓글