Linux awk 사용법 및 응용법.
awk에 대한 설명이 많고,
1. awk 란?
AWK(오크;Aho Weinberger Kernighan)는 유닉스에서 처음 개발된 일반 스크립트 언어입니다. AWK라는 이름은 이 스크립트 언어를 만든 앨프리드 에이호, 피터 와인버거, 브라이언 커니핸 세 명의 성의 앞글자를 따서 붙여졌다고 합니다. AWK의 기본 기능은 텍스트 형태로 되어있는 입력 데이터를 행과 단어 별로 처리해 출력하는 것입니다.
awk는 기본적으로 하나의 행을 레코드(Record)로 바라보며 처리합니다.
awk는 처리방식도 특이하고, 명령어를 스크립트처럼 사용할 수 있는 것이 특징입니다.
즉, 입력을 주어진 분리자(field seperator)로 분리하여 명령을 처리합니다.
2. awk 명령어
awk는 기본적으로 문장을 문자 단위로 나누며, default로 공백 기준으로 나눠서 출력해줍니다.
root@a8a8a006d4f3:/home/shell_script# cat txt.txt
A B C D E F G
root@a8a8a006d4f3:/home/shell_script# awk '{ print $1 }' txt.txt
A
root@a8a8a006d4f3:/home/shell_script# awk '{ print $2 }' txt.txt
B
root@a8a8a006d4f3:/home/shell_script#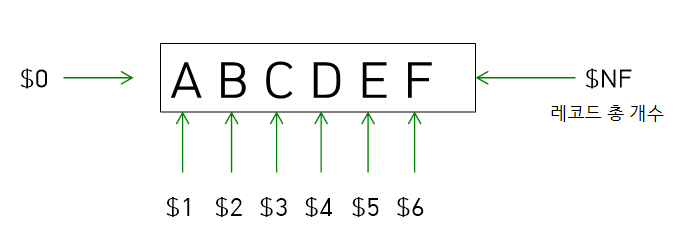
awk는 행 기준으로 출력을 하게 됩니다.
위 그림과 같이 표현되며 원하는 행을 '{ print }' 명령을 통해 출력할 수 있습니다.
F명령어.
-F를 통해 분리할 문자 혹은 문자열을 지정해주면 해당되는 문자 혹은 문자열을 지우고 지운 곳을 기준으로 문장을 나누게 됩니다.
root@a8a8a006d4f3:/home/shell_script# echo 'ABC-dev-test.zip' | awk -F- '{ print $1 }'
ABC
root@a8a8a006d4f3:/home/shell_script# echo 'ABC-dev-test.zip' | awk -F- '{ print $2 }'
dev
root@a8a8a006d4f3:/home/shell_script# echo 'ABC-dev-test.zip' | awk -F- '{ print $NF }'
test.zip
root@a8a8a006d4f3:/home/shell_script# echo 'ABC-dev-test.zip' | awk -F- '{ print $0 }'
ABC-dev-test.zip
root@a8a8a006d4f3:/home/shell_script#위 명령어에서 '-F' 옵션을 준 후 '-' 를 기준으로 분리시켰습니다.
root@a8a8a006d4f3:/home/shell_script# echo 'ABC-dev-test.zip hi test' \
> | awk -F- '{for(i=1;i<=NF;i++){print "Field Number:"i " Field value is: " $i}}'
Field Number:1 Field value is: ABC
Field Number:2 Field value is: dev
Field Number:3 Field value is: test.zip hi test이런식으로 awk 안에 for문을 넣어서 코딩하듯이 만들 수 있습니다.
그럼 -F가 해당 문자를 기준으로 레코드를 나눈다고 했는데, 어떻게 나누는지 보여드리겠습니다.
root@a8a8a006d4f3:/home/shell_script# echo 'ifslzf.zip' \
> | awk -F'.zip' '{for(i=1;i<=NF;i++){print "Field Number:"i " Field value is:" $i}}'
Field Number:1 Field value is:ifslzf
Field Number:2 Field value is:
root@a8a8a006d4f3:/home/shell_sc저는 ifslzf.zip을 넘겨 받아 awk -F 명령을 통해 '.zip' 이라는 이름을 기준으로 레코드를 나눴습니다.
$1 = ifslzf.zip
$2 = ''
이렇게 나뉘게 됩니다.
즉, .zip이 $2로 들어가는게 아니라 .zip은 사라지고 .zip기준으로 둘로 나눈 것이지요.
그럼 $2에는 공백이 들어가는데, 그 유이는 .zip 뒤에 아무런 문자열이 없기 때문에 공백이 default로 들어간 것입니다.
※무조건 둘로 나누는건 아닙니다. 아래 예시를 보시죠.
root@a8a8a006d4f3:/home/shell_script# echo 'ifslzf.zipABCD.zipTTT' \
> | awk -F'.zip' '{for(i=0;i<=NF;i++){print "Field Number:"i " Field value is:" $i}}'
Field Number:0 Field value is:ifslzf.zipABCD.zipTTT
Field Number:1 Field value is:ifslzf
Field Number:2 Field value is:ABCD
Field Number:3 Field value is:TTT
3. awk 응용법
1) 문자 하나만 제거하고 싶을때 '^'를 앞에 붙여주면 됩니다.
root@a8a8a006d4f3:/home/shell_script# echo 'LambdaIsGood!!Lambda' \
> | awk -F'^Lambda' '{for(i=1;i<=NF;i++){print "Field Number:$"i " Field value is:" $i}}'
Field Number:$1 Field value is:
Field Number:$2 Field value is:IsGood!!Lambda
root@a8a8a006d4f3:/home/shell_script#
2) git commit id만 보기.
root@a8a8a006d4f3:/home/coding_test# git log --pretty=tformat:"%H" --shortstat \
> | awk 'ORS = NR%3 ? " " : "\n"' | awk '{ print $1 }' | head -n 10
c6258e5c58c356df7662e21b3db396af522d99c8
4603839f41e73f62e6fdd1953e7dd22b2f322dc3
661bc5b308900889c062ef606b473825c25a807f
004f15684fecb8714ca1d4a570a6c45009809e5a
3b5bb72e80303ae31ed0c65238170937e04426ae
92c1c87c9abfc33183c44a0eccdba53355319ea0
147ca0cfed85e2b773843b774a4930a6b9d21fa9
410601c0aeaf69ca1d70f1f823eacdb9613dd2a4
b25e5f05258c702b11f2587187e7437bbefc8b97
67724e0a02b00d09055475b902f78170bf3a38d5
root@a8a8a006d4f3:/home/coding_test#